Was nützen mir klinische Studien?
Eine medizinische oder auch klinische Studie wird mit Patienten oder gesunden Probanden durchgeführt, um bestimmte Therapieformen, Medikamente, Medizinprodukte oder bestimmte Interventionen zu testen. Klinische Studien werden durchgeführt, um Aufschluss über wissenschaftliche Fragestellungen zu bekommen und bestenfalls eine Verbesserung der medizinischen Versorgung von Patienten zu erreichen.
Medizinische Studien können ebenfalls Fehlern oder systematischen Einschränkungen unterliegen, so dass gewonnene Erkenntnisse und veröffentliche Empfehlungen durchaus kritisch hinterfragt werden sollten. Die Fähigkeit, Informationen aus medizinischen Studien zu lesen, verstehen und zu verwenden, macht Patienten zu aufgeklärten Patienten und erscheint vor dem Hintergrund der vielfältigen (politischen) Interessensvertretungen im Gesundheitswesen als sehr wichtig.
Die medizinische Behandlung von Krankheiten ist auf gesicherte, möglichst objektive Daten angewiesen, die auf standardisierten und nachvollziehbaren Wegen gewonnen wurden. Jedes Medikament und auch jedes Diagnoseinstrument muss durch festgelegte Anforderungen überprüfbar sein. Im medizinischen Alltag darf eine Neuerung in der Regel nur dann angewandt werden, wenn die Wirksamkeit belegt und schwerwiegende Nebenwirkungen ausgeschlossen werden konnten.
Zur Überprüfung von Therapien und zur Beurteilung von Therapieempfehlungen benötigt man Studien, welche Beweise für die Wirksamkeit und Sicherheit, erbringen. Allgemein gilt, dass alle Ergebnisse von Studien nur Schätzwerte liefern. Ob diese Effekte in Wirklichkeit so eintreten, kann nicht sicher gesagt werden. Auch bei einem so genannten signifikanten Ergebnis kann der Therapieeffekt in Wahrheit sowohl größer als auch kleiner sein. Insbesondere bei Studien mit kleinen Fallzahlen ist die Gefahr groß, dass die Ergebnisse nur zufällig sind.
Was ist „Evidenz-basierte Medizin (EbM)“?
Die Methoden der evidenz-basierten Medizin ermöglichen eine objektive und nachvollziehbare Bewertung medizinischer Studien. Bei dem Begriff Evidenz handelt es sich um das eingedeutschte englische Wort „evidence“, das Beweis bedeutet. Zur Überprüfung von Therapien und zur Beurteilung von Therapieempfehlungen benötigt man Studien, welche diese Evidenz, also Beweise für die Wirksamkeit und Sicherheit, erbringen. Die beste Evidenz für die Wirksamkeit und für Nebenwirkungen verschiedener Behandlungsarten liefern randomisiert-kontrollierte Studien.
Medizinische Forschung
Grundsätzlich wird in der medizinischen Forschung die Primär- von der Sekundärforschung unterschieden. In der Primärforschung werden Studien durchgeführt und in der Sekundärforschung bereits vorhandene Ergebnisse aus Studien (systematisch) zusammengefasst. Die quantitative Primärforschung gliedert sich in weitere drei Hauptbereiche:
- medizinische Grundlagenforschung
- klinische Forschung und
- epidemiologische Forschung.
Die unten stehende Grafik gibt einen Überblick über verschiedene Forschungsdesigns, wobei eine genaue Zuordnung teilweise schwierig ist. Für die MS-Forschung und dieses Wiki wird hier auf besonders relevante Forschungsmethoden (z.B. RCT und Prognosestudien) genauer eingegangen.
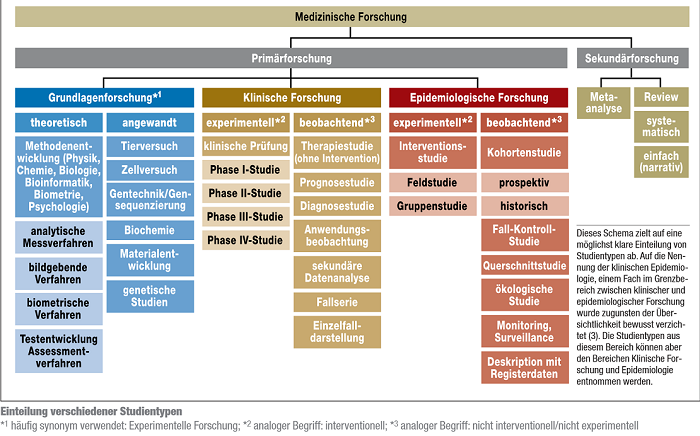
Abb.: Studiendesigns[1]
Zur Grundlagenforschung (auch experimentelle Forschung genannt) zählen zum Beispiel Zell- und Tierversuche, Studien zu Arzneimitteleigenschaften, physiologische und genetische Untersuchungen. Zudem stellen die Entwicklung und Verbesserung bildgebender (z.B. Magnetresonanztomografie) und analytischer Messverfahren (z.B. Bestimmung von Genen und Enzymen) sowie die Entwicklung von statistischen Testverfahren wichtige Bereiche der Grundlagenforschung dar.[1]
Die klinische Forschung gliedert sich in die Durchführung von experimentellen (interventionellen) und beobachtenden (nicht interventionellen) Studien. Bei einer klinischen (Arzneimittel-) Prüfung, handelt es sich um eine klinische experimentelle Studie bei der nach dem Arzneimittelgesetz § 4 eine Untersuchung am Menschen unternommen wird, um die Wirkung von Arzneimitteln nachzuweisen bzw. zu erforschen (auch Nebenwirkungen, Aufnahme und Verteilung im Stoffwechsel und Ausscheidung) und die Unbedenklichkeit oder Wirksamkeit der Arzneimittel nachgewiesen werden soll. Hierbei werden die Studien weiter in Phase I- bis Phase IV-Studien unterteilt. Auf die verschiedenen Phasen wird im Folgenden genauer eingegangen:
- Phase I: Humanpharmakologie
Erste Erprobung eines Arzneimittels an zumeist gesunden Menschen. Ziel ist es, durch eine ein- oder mehrmalige Gabe die Unbedenklichkeit eines Medikaments zu bewerten und Ergebnisse zu gewinnen, wie der Wirkstoff vom menschlichen Körper aufgenommen, verteilt, verstoffwechselt, abgebaut und ausgeschieden wird.

- Phase II: Therapeutische Erprobung
Zumeist wird mit einer kleinen Fallzahl an kranken Menschen die Wirksamkeit getestet und zugleich die richtige Dosis gesucht.

- Phase III: Therapeutische Bestätigung
In dieser Phase wird die Untersuchung mit einer festgelegten Dosierung sowie bestimmten Sicherheits- und Wirksamkeitsparametern mit einer relativ großen Patientengruppe durchgeführt. Es soll nachgewiesen werden, dass der Wirkstoff einen Einfluss auf krankhafte Ausgangswerte hat. Deshalb erhält eine Vergleichsgruppe einen Scheinwirkstoff (Placebo). In der Regel findet die Anwendung über einen längeren Zeitraum statt.

- Phase IV: Therapeutische Anwendung
Hierzu gehören alle Studien, die nach der Zulassung eines Wirkstoffes durchgeführt werden. Sie dienen unter anderem zur weiteren Abschätzung der Risiken und des Nutzens eines Medikaments. So können beispielsweise sehr seltene Nebenwirkungen eines Medikaments nur festgestellt werden, wenn sehr viele Menschen über einen längeren Zeitraum beobachtet werden (Vergleich mit einer Kontrollgruppe). Zudem sollen Erkenntnisse gewonnen werden, wie sich das Medikament im Alltag oder im Vergleich mit anderen Medikamenten bewährt (Starke und Geisslinger, 2005).

- Phase V: Nutzenbewertung
Als eine weitere fünfte Phase ließe sich die Nutzenbewertung eines Medikaments durch das Institut für Qualität und Wirtschaftlichkeit im Gesundheitswesen (IQWiG) bestimmen. "Im Rahmen seiner Aufgabe, den Gemeinsamen Bundesausschuss (G-BA) und den Spitzenverband der gesetzlichen Krankenversicherung (GKV-Spitzenverband) bei der Erfüllung ihres gesetzlichen Auftrags zu unterstützen, bewertet das Institut für Qualität und Wirtschaftlichkeit im Gesundheitswesen (IQWiG) Nutzen und Schaden von medizinischen Interventionen sowie deren wirtschaftliche Implikationen, um zu einer kontinuierlichen Verbesserung der Qualität und Effizienz der Gesundheitsversorgung der deutschen Bevölkerung beizutragen" (Zitat: IQWiG, 2009).[2]

Bei nicht interventionellen klinischen Studien handelt es sich um patientenbezogene Beobachtungsstudien, innerhalb derer Patienten eine individuell abgestimmte Therapie erhalten. Die Form der Therapie wird abhängig von Diagnose und Patientenwunsch mit dem behandelnden Arzt festgelegt. Prognosestudien, Anwendungsbeobachtungen und Einzelfallserien zählen beispielsweise zu den nicht interventionellen Studien.[1]
Wichtige Studiendesigns
Randomisiert-kontrollierte Studie (RCT)
Ein Studienergebnis kann durch die Auswahl der untersuchten Patienten erheblich verfälscht werden, vor allem durch das Fehlen der Ergebnisse jener Patienten, die vorzeitig eine Studie abgebrochen haben. Zur Auswertung wird heutzutage deshalb eine so genannte „Intention-to-treat“ (ITT)-Analyse gefordert. Studienteilnehmer, die eine Behandlung abbrechen, werden später mit in die Bewertung einbezogen, als ob sie die Therapie bis zum Schluss durchgehalten hätten. Mit diesem Vorgehen will man sicherstellen, dass Therapieeffekte nicht überschätzt werden.
Metaanalyse/ Übersichtsarbeit
Eine Metaanalyse fasst die Ergebnisse mehrerer Studien mit mathematisch-statistischen Methoden zusammen. Hierbei sollte es sich idealerweise um vergleichbare Studien handeln. Die Metaanalyse zählt zu der Sekundärforschung.
Kohortenstudien/ Prognosestudien
Durch Prognosestudien wird u.a. der Verlauf einer Erkrankung ohne Therapie (natürlicher Verlauf) und auch unter einer bestimmten Behandlung untersucht.[3] Da MS eine chronische Erkrankung ist und oftmals erst nach Jahrzehnten zu bleibenden Beeinträchtigungen führt, müssen Betroffene über lange Zeit beobachtet werden, um Aussagen über die Entwicklung der Erkrankung machen zu können. Es gibt nur wenige Prognosestudien, welche alle MS-Betroffenen einer Region eingeschlossen haben (streng populationsbasiert). Durch Veränderungen in der Stellung der Diagnose der MS und auch der vorhandenen Therapiemöglichkeiten müssen die Ergebnisse älterer Prognosestudien mit Vorsicht betrachtet werden.
Was heißt populationsbasiert?
Eine Prognosestudie erfolgt am besten populationsbasiert, das heißt, man versucht alles, um alle Patienten (die „Population“) einer bestimmten Region zu erfassen. Das ist insofern wichtig, als das die Einschätzung sonst verzerrt ist, wenn nur besonders schwer betroffene Patienten beobachtet werden. Diese Gefahr besteht z.B. in MS-Schwerpunktzentren, wo viele Patienten mit ungünstigen Verläufen behandelt werden. Auf diese Weise kann die Erkrankung schlimmer erscheinen, als sie in Wirklichkeit ist. Hier spricht man von einer zentrumsbasierten Studie.
Wie lang muss eine Prognosestudie sein?
Eine Prognosestudie bei MS muss, um wirklich sicher Beeinträchtigungen erfassen zu können, über einen längeren Zeitraum laufen, also möglichst mindestens über 10 Jahre. Solche Studien sind daher teuer und aufwändig.
Was sind mögliche Zielparameter /Endpunkte für Prognosestudien?
Wichtig für eine Prognosestudie sind im Allgemeinen gut zu erhebende Zielparameter bzw. Endpunkte, wie z.B. der Tod durch die Erkrankung („Mortalität“). Da der Tod durch MS eine Seltenheit ist, hat man hier in den großen Prognosestudien Meilensteine in der Beeinträchtigung analysiert. Die Beeinträchtigung von MS-Patienten wird mit einer neurologischen Skala gemessen, der „Expanded- Disability-Status-Scale“ (EDSS) nach Kurtzke[4] auf Deutsch „Erweiterte Beeinträchtigungsskala“. Die Einordnung in dieser Skala erfolgt durch eine neurologische Untersuchung. Hier steht die Beeinträchtigung des Gehens sehr im Vordergrund.
Die EDSS reicht von 0 = „keine Beschwerden“ in Schritten von 0,5 bis hin zu 10 = „Tod durch MS“. Natürlich kann man die vielen sehr unterschiedlichen Arten von MS-typischen Beeinträchtigungen nicht wirklich mit einer einzigen Skala darstellen.
Anders ausgedrückt: Es ist sehr schwierig, einen Betroffenen mit seinen ganz persönlichen Beeinträchtigungen einzuordnen oder mit anderen Betroffenen bezüglich des Schweregrades zu vergleichen. Um es doch zu versuchen, misst die Skala auf unterschiedlichen Abschnitten unterschiedliche Beeinträchtigungen. Von „0“ bis „3,5“ wird der EDSS-Wert im Rahmen einer neurologischen Untersuchung bestimmt. Von „4“ bis „7“ beruht der Wert auf der maximalen Gehstrecke. Bei den Werten über „7“ entscheidet das Ausmaß der Pflegebedürftigkeit. Damit sind die Abstände zwischen den Zahlenwerten je nach Bereich der Skala sehr unterschiedlich. So ist z.B. der Sprung von 6,0 bis 6,5 viel größer als von 1 auf 1,5.
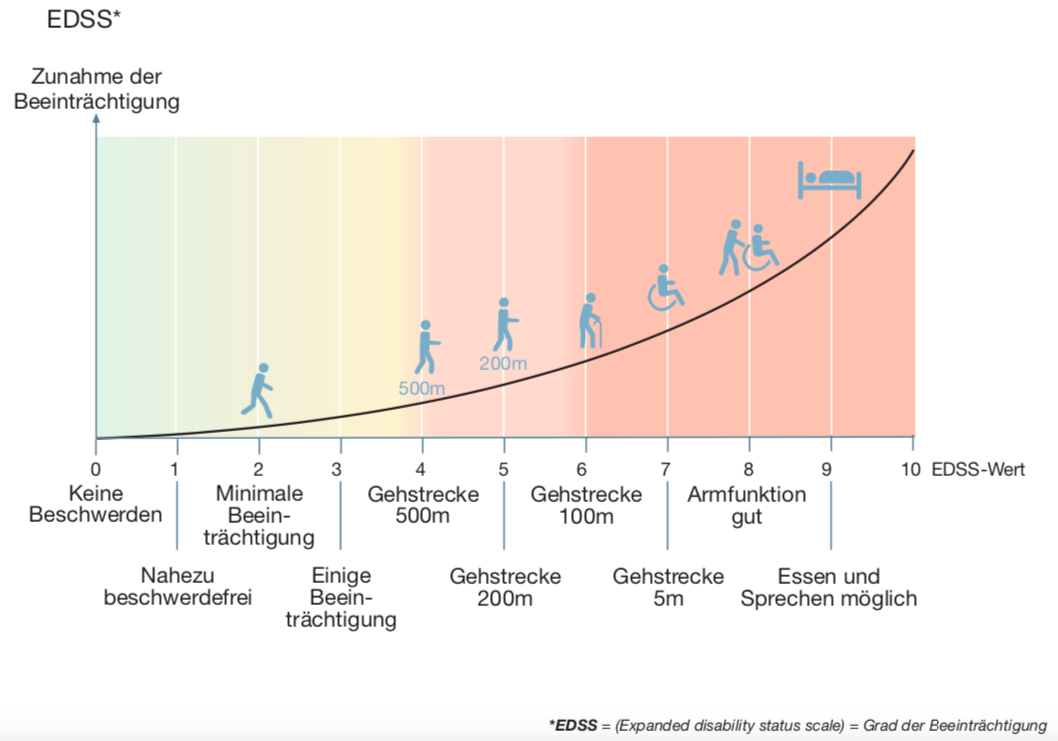
Meilensteine der Beeinträchtigung
Üblicherweise werden bei der Betrachtung des MS-Verlaufs v.a. drei wichtige Beeinträchtigungswerte („Meilensteine“) betrachtet. Im Vordergrund steht bei den Meilensteinen die Beeinträchtigung des Gehvermögens. Dies sind die Gehstrecke bis zu 500m (EDSS 4,0), bis 100m (EDSS 6,0) und bis 5m (EDSS 7,0). Andere Beeinträchtigungen, wie z.B. Sehstörungen oder Hirnleistungsstörungen sind kaum über lange Zeit untersucht worden.
Unsicherheit der Krankheitsdauer – Beginn der MS
Das Alter zu Beginn der MS wird oft als prognostischer Faktor untersucht. Oft ist jedoch der Erkrankungsbeginn nicht genau feststellbar. Denn häufig gehen der Diagnosestellung kleinere Ereignisse voraus, die Schübe gewesen sein könnten. Diese sind möglicherweise Jahre vor der Diagnosestellung aufgetreten, und nicht selten liegen keine medizinischen Aufzeichnungen darüber vor.
Diagnostische Tests
Diagnosestudien werden durchgeführt, um die Güte von diagnostischen Tests zu überprüfen (siehe auch 2.4 und 2.5).
Diagnostische Tests helfen eine Diagnose zu stellen. Diagnostische Tests können sehr unterschiedliche Dinge sein: z.B. Informationen aus einem Gespräch mit dem Arzt, Untersuchungsergebnisse aus dem Blut oder dem Nervenwasser, Kernspinbilder oder Nervenmessungen. Je besser eine Erkrankung verstanden ist, desto eindeutiger sind die Testergebnisse. So lässt sich zum Beispiel ein Beinbruch meist sehr schnell schon durch die körperliche Untersuchung, spätestens durch ein Röntgenbild feststellen.
Goldstandard
Um einen neuen Test zu überprüfen, braucht man einen so genannten Vergleichstandard (auch „Goldstandard“ genannt). Das ist ein etablierter Test, der möglichst sicher eine Diagnose anzeigt. Jeder neue Test muss im Vergleich mit dem derzeit etablierten Goldstandard Vorteile aufzeigen (z.B. höhere Genauigkeit, einfachere praktische Durchführung und/oder geringere Kosten). Oft handelt es sich bei dem Goldstandard um einen besonders aufwändigen bzw. teuren Test wie z.B. die Entnahme von Körpergewebe bei Verdacht auf einen Tumor.
Wann ist ein neuer Test besser als ein alter?
Es gibt viele Gründe, warum ein neuer Test einen alten Test ersetzen sollte. Meist handelt es sich um genauere Tests, weniger aufwändige bzw. günstigere Tests oder Tests, die schneller ein Ergebnis zeigen als bisher. Da eine Diagnose in der Regel eine Behandlung nach sich zieht, kann umso erfolgreicher behandelt werden, je genauer der diagnostische Test ist. Daher sollte ein guter Test in letzter Konsequenz zu mehr Gesundheit führen.
Dies kann nur mit einer randomisiert kontrollierten Studie nachgewiesen werden. Eine Gruppe von Patienten wird mit einem herkömmlichen Test untersucht, eine andere Gruppe zusätzlich oder alternativ mit dem neuen Test. Ein Test, der nur früher zeigt, dass man eine bestimmte Krankheit hat, ohne dass dadurch eine bessere Therapiemöglichkeit entsteht, ist fragwürdig. In der Medizin gibt es viele Beispiele, bei denen eine frühere Diagnose mit neuen Tests zwar möglich, ihre Anwendung jedoch umstritten ist. Zum Einen entstehen bei manchen Erkrankungen nach frühzeitiger Diagnose keine Konsequenzen für die Therapie, z.B. weil es keine gibt. Zum Anderen kann das frühe Wissen um eine Erkrankung auch eine Belastung sein.
Sensitivität und Spezifität
Sensitivität und Spezifität sind wichtige Kenngrößen, die die Qualität eines diagnostischen Tests beschreiben.
Die Sensitivität ist dabei ein Wahrscheinlichkeitswert, der anzeigt, wie sicher der Test eine vorliegende Erkrankung erkennt. Der Wert beurteilt einen Test aus der Perspektive von sicher Erkrankten: „Wenn die Krankheit vorliegt, wie sicher wird sie durch den Test erkannt?“ Bei einer Sensitivität von 100% werden alle Kranken auch als erkrankt (positiv) gestestet, bei 75% werden 75 von 100 Erkrankten erkannt. Allerdings werden dann 25% oder einer von 4 Erkrankten fälschlicherweise nicht erkannt, sie haben ein „falsch negatives“ Testergebnis, weil der Test sie fälschlicherweise als gesund eingeschätzt hat.
Die Spezifität beschreibt, wie genau ein Test nicht erkrankte Menschen richtig als nicht erkrankt erkennt. Eine Spezifität von 100% zeigt an, dass alle Menschen, die von der Krankheit nicht betroffen sind, auch als solche (negativ) gestestet werden. Bei einer Spezifität von 75%, werden 3 von 4 Gesunden als solche erkannt. Allerdings werden dann 25% oder einer von 4 fälschlicherweise nicht erkannt, sie haben ein „falsch positives“ Testergebnis, weil der Test sie fälschlicherweise als krank eingeschätzt hat.
Wann ist die Milch sauer? (Ein Bespiel zum Verständis)
Das Haltbarkeitsdatum von Frischmilch kann als „diagnostischer Test“ für die Eigenschaft „frisch“ oder „sauer“ benutzt werden. Genauso wie die Milch möglicherweise länger haltbar ist, als auf der Packung angegeben, so ist sie möglicherweise schon früher als angegeben nicht mehr genießbar. Die Sensitivität des Haltbarkeitsdatums ist hoch, wenn sehr viele Tüten mit saurer Milch auch tatsächlich abgelaufen sind. Das kann man erreichen, wenn man das Haltbarkeitsdatum verkürzt. Die Spezifität des Haltbarkeitsdatums ist hoch, wenn sehr viele Tüten mit frischer Milch noch nicht abgelaufen sind. Das kann man erreichen, wenn man das Haltbarkeitsdatum verlängert. An dem Beispiel sieht man, dass Sensitivität und Spezifität eng verbunden sind. Verlängert man das Verfallsdatum, werden weniger Tüten mit frischer Milch abgelaufen sein, es gibt also wenig „falsch positive“ Ergebnisse. Die Spezifität ist hoch.
Gleichzeitig werden aber mehr Tüten mit saurer Milch nicht abgelaufen sein, es gibt also mehr „falsch negative“ Ergebnisse: die Sensitivität ist niedrig. Beim Einsatz des Haltbarkeitsdatums kommt es jedoch darauf an möglichst wenig saure Milch zu übersehen, also möglichst wenig „falsch negative“ Ergebnisse und somit eine hohe Sensitivität zu erreichen. Das heißt, es ist wichtiger, die saure Milch herauszufiltern als sicher alle trinkbare Milch zu erfassen. So nimmt man eher in Kauf, dass frische Milch mit abgelaufenem Haltbarkeitsdatum weggeworfen wird, als dass saure Milch als frisch verkauft wird.
Die nachfolgende Abbildung soll das verdeutlichen.
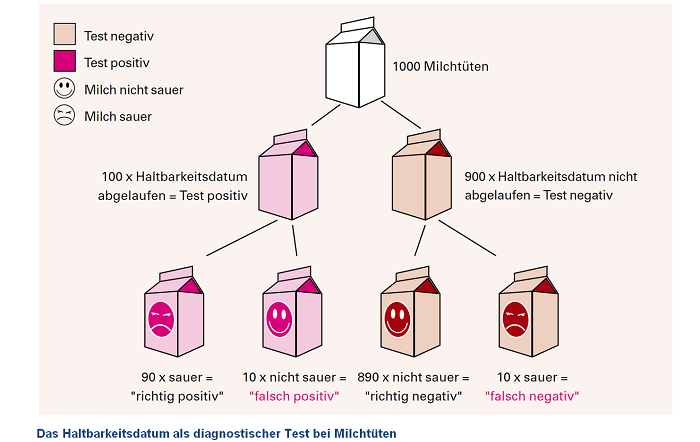
Die Vorhersagewerte oder prädiktiven Werte beschreiben die Qualität von Tests aus dem Blickwinkel positiver Tests (positiv prädiktive Werte) und negativer Tests (negativ prädiktive Werte). Der positiv prädiktive Wert gibt an, wie aussagekräftig ein positives Ergebnis ist, also wie viele Menschen mit einem positiven Test tatsächlich krank sind. Der negativ prädiktive Wert gibt an, wie aussagekräftig ein negatives Ergebnis ist, also wie viele Menschen mit einem negativen Test tatsächlich nicht erkrankt sind.
Endpunkte
Der Endpunkt bezeichnet das Studienziel bzw. das Zielkriterium, mit dem der Erfolg der Therapie bewertet werden soll, z.B. das Verhindern von Schüben. Oft haben Studien mehrere Endpunkte. Man spricht dann beim Hauptendpunkt vom „primären Endpunkt“, bei allen weiteren von „sekundären Endpunkten“. Für einen Wirksamkeitsnachweis wird immer ein Ergebnis bezogen auf den primären Endpunkt erwartet. Oft werden bei Studien ohne überzeugendes Ergebnis im primären Endpunkt die Ergebnisse der sekundären Endpunkte betont, bei denen ein Vorteil für das Medikament gezeigt wurde. Dies darf nur mit Vorbehalt positiv bewertet werden, da mit zunehmender Anzahl an Berechnungen das Risiko steigt, zufällig ein solches Ergebnis zu finden.
Statistische Auswertung von Studiendaten
Statistische Signifikanz
Die statistische Auswertung der Studienergebnisse hat ergeben, dass diese mit hoher Wahrscheinlichkeit nicht auf Zufall beruhen (siehe auch Klinische Relevanz).
Vertrauensbereich, oder auch Konfidenzintervall
Hiermit wird die Genauigkeit des Ergebnisses angegeben. Je größer der Vertrauensbereich, desto ungenauer das Ergebnis. Bei Studien mit vielen Teilnehmern ist der Vertrauensbereich kleiner und das Ergebnis somit genauer. Zwei von uns erstellte und evaluierte Erklärungsvideos zu Vertrauensbereichen (am Beispiel Durschnittsgewichte und Apfelbehandlung) mit den von uns verwendeten Grafiken gibt es hier.
Analyse von Teilgruppen („Subgruppenanalyse“)
Nach Studienabschluss finden oft so genannte „Subgruppenanalysen“ statt. Das heißt, es werden Patientengruppen herausgefiltert, bei denen sich ein (deutlicherer) Effekt einer bestimmten Therapie zeigen lässt. Das ist problematisch, da das Risiko steigt, nur zufällig signifikante Ergebnisse zu finden.
Klinische Relevanz
Ein „statistisch signifikantes“ Studienergebnis heißt nicht, dass es auch bedeutsam oder „klinisch relevant“ für den Patienten sein muss. Zum Beispiel kann der Nutzen einer Therapie sehr klein sein oder nur auf einen nicht bedeutsamen Endpunkt bezogen sein. Aus praktischen Gründen wurde vereinbart, dass eine Irrtumswahrscheinlichkeit von maximal 5% als akzeptabel angenommen wird (p=0,05). Dies entspricht der so genannten statistischen Signifikanz oder dem so genannten P-Wert. Das Risiko, dass ein bestimmtes Ergebnis doch nur zufällig ist, liegt demnach bei 5%. Studien mit vielen Teilnehmern finden tatsächlich bestehende Unterschiede zwischen zwei Gruppen leichter heraus. Je größer die Studie desto geringer ist die Gefahr, einen vorhandenen Unterschied zu übersehen. Diese Wahrscheinlichkeit wird als „Power“ bezeichnet. Je kleiner eine Studie, desto größer ist das Risiko, einen tatsächlich vorhandenen Effekt zu übersehen.
Einschlusskriterien
Einschlusskriterien bezeichnen die Kennzeichen, die ein Patient besitzen muss, um an einer bestimmten Studie teilnehmen zu können, z.B. einen bestimmten Beeinträchtigungsgrad. Aussagen zur Wirksamkeit eines Medikaments können nur für die jeweils in die Studie einbezogenen Patienten gemacht werden. Insofern ist es von großer Bedeutung, in der Planung einer Studie die Eigenschaften der Teilnehmer festzulegen, die eingeschlossen werden sollen. Dabei ist die Frage leitend: Für welche Gruppe von Patienten soll die Gruppe der Studienteilnehmer repräsentativ sein? Nur für solche Patienten ist dann ein Studienergebnis auch gültig.